以下为引用的内容:
记者:为什么对同一词条,百度与其他搜索引擎出来的结果不一样呢?
李彦宏:比如,在百度,检索词越长,用户找到的检索数目就越少。因为,我们认为用户检索的所有词语都应该出现,这样才能确保检索的精确性。但在谷歌或西方的搜索引擎,检索词越长,检索到的信息就越多。它们认为,与检索词中任一词语相关的信息都应该出现。换句话说,百度采用的是“与”逻辑,而谷歌或西方的搜索引擎采用的则是“或”逻辑。对用户来说,检索结果数量的多少并没有太大价值,最关键的是,他想要找的东西找到没有。
实验的第一个页面标题:李彦宏为什么吃饭?
实验的第二个页面标题:李彦宏为什么吃饭还要拿筷子?
实验的第三个页面标题:李彦宏为什么还要拿筷子吃饭?
实现前搜索结果:

测试一小时后就收录了,当然结果也出来了。
试验后结果图片:

李彦宏为什么吃饭还要拿筷子
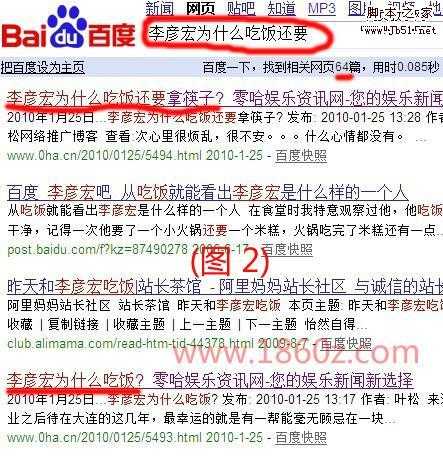
李彦宏为什么吃饭还要
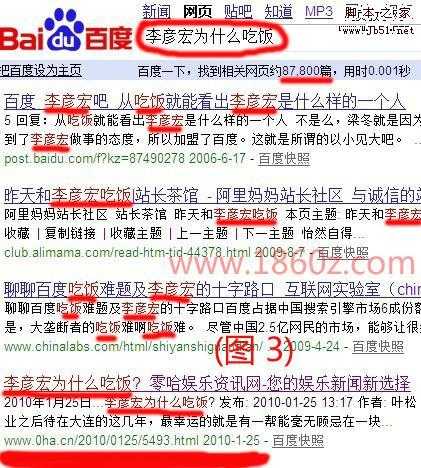
李彦宏为什么吃饭
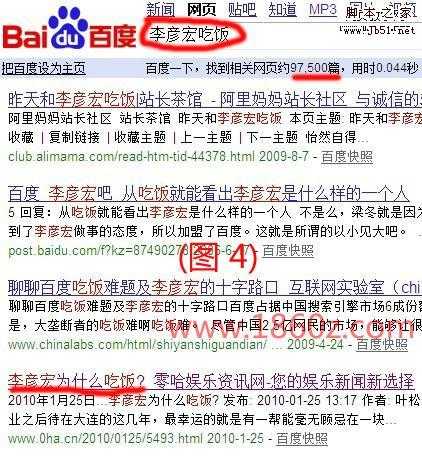
李彦宏吃饭


从试验后图片1中的结果可以看出,百度对完全匹配的检索词给予很高的分值,即使检索词的排序不同,只要这些词全部包含在页面中,都是可以加分的,这同样也能解析关键词堆砌对百度有用,而对google无用,了解了这些,也对大家做长尾关键词有个很好指导,而从以上四张图片中也验证了李彦宏所说的话:检索词越长,检索到的结果越少。大家有兴趣的自己可以再对比下google的结果,这就不难解析,为什么搜索一些词google的结果会多些了,两者的差异:百度采用的是“与”逻辑,而谷歌或西方的搜索引擎采用的则是“或”逻辑。
此实验并未考虑排名的其它因素(比如外链,网站权重,检索词出现的次数等),所以排名只能横向对比,就是看我的三个实验页面的结果进行对比。(现在大家应该知道李彦宏吃饭为什么用筷子了吧!)以上只是个人看法,也非常欢迎大家有不同的看法一起交流。
原文链接地址: http://www.1860z.com/1109.html 作者:叶松
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]