一、前提条件
- 安装了Fiddler了(用于抓包分析)
- 谷歌或火狐浏览器
- 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器
- 有Python的编译环境,一般选择Python3.0及以上
声明:本次爬取腾讯视频里 《最美公里》纪录片的评论。本次爬取使用的浏览器是谷歌浏览器
二、分析思路
1、分析评论页面

根据上图,我们可以知道:评论使用了Ajax异步刷新技术。这样就不能使用以前分析当前页面找出规律的手段了。因为展示的页面只有部分评论,还有大量的评论没有被刷新出来。
这时,我们应该想到使用抓包来分析评论页面刷新的规律。以后大部分爬虫,都会先使用抓包技术,分析出规律!
2、使用Fiddler进行抓包分析——得出评论网址规律
fiddler如何抓包,这个知识点,需要读者自行去学习,不在本博客讨论范围。

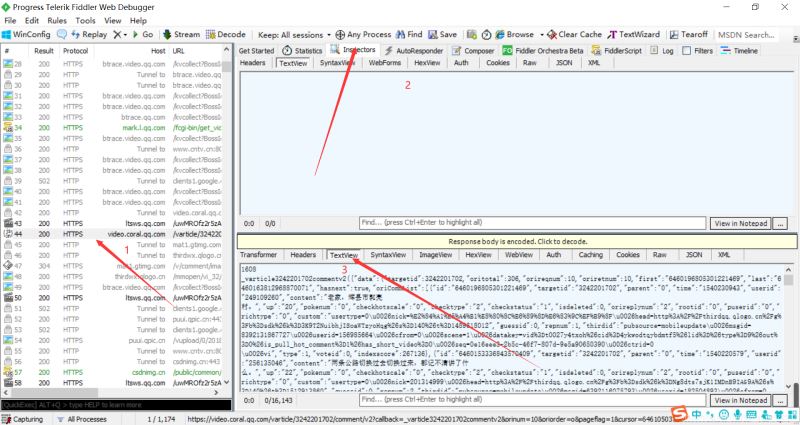
把上面两张图里面的内容对比一下,可以知道这个JS就是评论存放页面。(这需要大家一个一个找,一般Ajax都是在JS里面,所以这也找JS进行对比即可)
我们复制这个JS的url:右击 > copy > Just Url
大家可以重复操作几次,多找几个JS的url,从url得出规律。下图是我刷新了4次得到的JS的url:

根据上图,我们发现url不同的地方有两处:一是cursor=?;二是_=?。
我们很快就能发现 _=?的规律,它是从1576567187273加1。而cursor=?的规律看不出来。这个时候找到它的规律呢?
(1)百度一下,看前人有没有爬取过类型的网站,根据他们的规律和方法,去找出规律;
(2)羊毛出在羊身上。我们需要有的大胆想法——会不会这个cursor="htmlcode">
url = https://video.coral.qq.com/varticle/3242201702/comment/v2"text-align: center">
如下:
一般情况下,我们还要多试几次,确定我们的想法是正确的。
至此,我们发现了评论的url之间的规律:
- _=?从1576567187273加1
- cursor=?的值存在上面一个JS中。
三、代码编写
import re
import random
import urllib.request
#构建用户代理
uapools=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0",
]
#从用户代理池随机选取一个用户代理
def ua(uapools):
thisua=random.choice(uapools)
#print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#设置为全局变量
urllib.request.install_opener(opener)
#获取源码
def get_content(page,lastId):
url="https://video.coral.qq.com/varticle/3242201702/comment/v2"+lastId+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_="+str(page)
html=urllib.request.urlopen(url).read().decode("utf-8","ignore")
return html
#从源码中获取评论的数据
def get_comment(html):
pat='"content":"(.*"'
rst = re.compile(pat,re.S).findall(html)
return rst
#从源码中获取下一轮刷新页的ID
def get_lastId(html):
pat='"last":"(.*"'
lastId = re.compile(pat,re.S).findall(html)[0]
return lastId
def main():
ua(uapools)
#初始页面
page=1576567187274
#初始待刷新页面ID
lastId="6460393679757345760"
for i in range(1,6):
html = get_content(page,lastId)
#获取评论数据
commentlist=get_comment(html)
print("------第"+str(i)+"轮页面评论------")
for j in range(1,len(commentlist)):
print("第"+str(j)+"条评论:" +str(commentlist[j]))
#获取下一轮刷新页ID
lastId=get_lastId(html)
page += 1
main()
四、结果展示

总结
以上所述是小编给大家介绍的Python爬取腾讯视频评论,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]